
A product marketing manager’s attempt at AI agent clarity
I attended the recent Product Marketing Alliance (PMA) Boston meetup, and the question came up about what an agentic application is and how it compares with a traditional software application. We discussed a bit, I learned, I posited, and the discussion later sent me down a terminology and description rat hole. In the coming days, I read and ruminated. Why does the label matter? Did I mis-label my own AI application? Are people talking about the same thing? What is the key to “agentic?”
As a word guy, it bothers me that many people say AI when they mean so many different things. So, I spent time interacting with Claude and Perplexity, read some great essays, and chatted with a long-time friend and PhD big data / AI expert. And here is the result.
Author AI disclosure: This essay comes from an original draft I wrote, fed to Claude for corrections, incorporated feedback from my friend, re-org’d and additions by me, and further Claude re-org and suggested re-writes, and heavy editing and updates from me as the last step. I welcome feedback!
Why is a Product Marketing Manager writing this
I’m a product marketer. Not a programmer. Not an AI engineer. So why am I trying to define the differences between a workflow and an agent?
The words we use to describe a product
shape what customers expect it to do.
Currently, the words agent and agentic are getting slapped on anything with an LLM call somewhere inside it. Or it is purely an LLM prompt wrapped with a UI text box. This isn’t a nit. It fundamentally changes what buyers think they’re getting. It changes what engineering commits to building. And it changes what your executive team thinks you’re spending money on.
This is my attempt at vocabulary clarity, written for other product marketing folks who have been asked some version of “wait, what’s the actual difference?” and want to answer without bluffing. At the same time, I’m not overpromising (this stuff is all new!) or going down to define a deeper architectural level.
As an explainer and a translator, I’ll address one place where I had to update my own understanding, including a section where I admit, in writing, that I previously mislabeled my own tool (oops!) More on that in a moment…
The thread:
Who decides what to do next?
Everything below can be framed by a single question.
Who (or what) picks the next step?
At one end of the spectrum, a human designer figures out the entire path an application takes ahead of time, and the programming follows it. At the other end, an LLM picks its own next move at runtime, based on what it just observed. (Perhaps that move makes a request of a human, of some existing code, or even of another AI agent.)
Most real-world systems live somewhere on a spectrum between those poles. That spectrum is the key. Hold onto that.

Shelly Palmer, reflecting a talk Anthropic’s Barry Zhang gave at the AI Engineer Summit, lays the field out in three terms:
- Task (“single model call”)
- Workflow (“Multiple model calls in a predefined control flow. You decide the steps, the model fills them in.”)
- Agent (“A model using tools in a loop, deciding its own trajectory. You give it a goal, a set of tools, and a system prompt. It decides what to do next based on what just happened”). (Palmer)
I extend that to four approaches, because I think there’s a meaningful distinction between an application that uses a single-pass LLM call and LLM orchestration where a human lays out a logical order of multiple LLM calls. I believe the distinction between traditional programming, a single-pass LLM, and orchestrated LLM calls helps build a foundation where the workflow-vs-agentic distinction lands better.
Here is my four-approach taxonomy
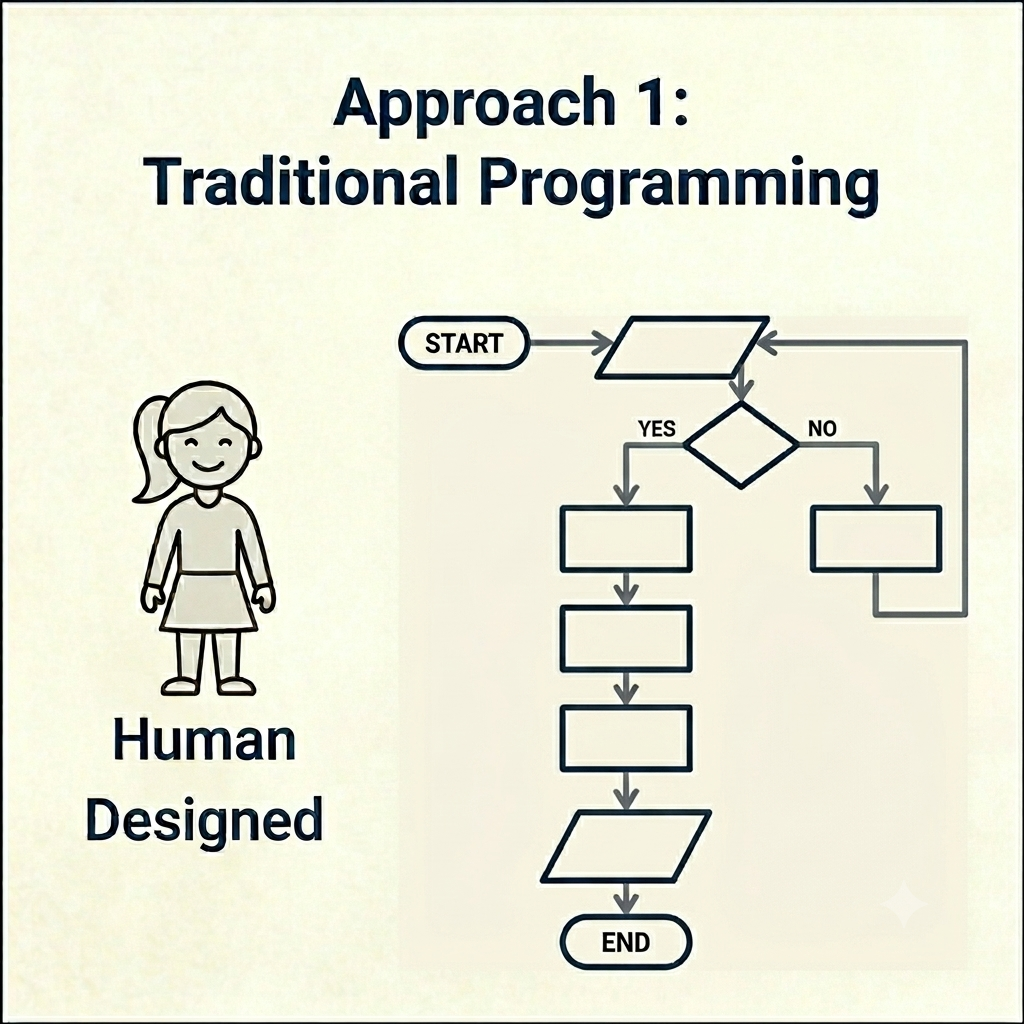
Approach 1.
Traditionally programmed solution
In this approach, a set of operations is performed in a specific order against a defined set of data. The steps can be gated by all sorts of logic (if-then, case statements, try/except/finally, even GOTO if you’re feeling nostalgic), but the path itself is something the architect conceives of ahead of time. The complexity of the planning and the branching doesn’t change the fact that a human decided the next step in each case. Every decision and branch is one a human anticipated and coded.
Whether these steps are a simple atomic task, are modularized and reused across one deployment, several programs, or larger systems, the approach is that a human decided each step.
An example is a mortgage app that takes interest rate, term, and principal from the user, calculates an amortization table, renders the payment curve on screen, and emails a PDF. Predictable inputs, predictable steps, predictable output.
Another example is a UI designed to extract pre-written articles from a database, perhaps tagged by topic or located by strings, and assembles a list of allegedly relevant target materials. It’s merely filtering and templating. A human has decided what the tags mean and controls what gets returned based on structured queries.
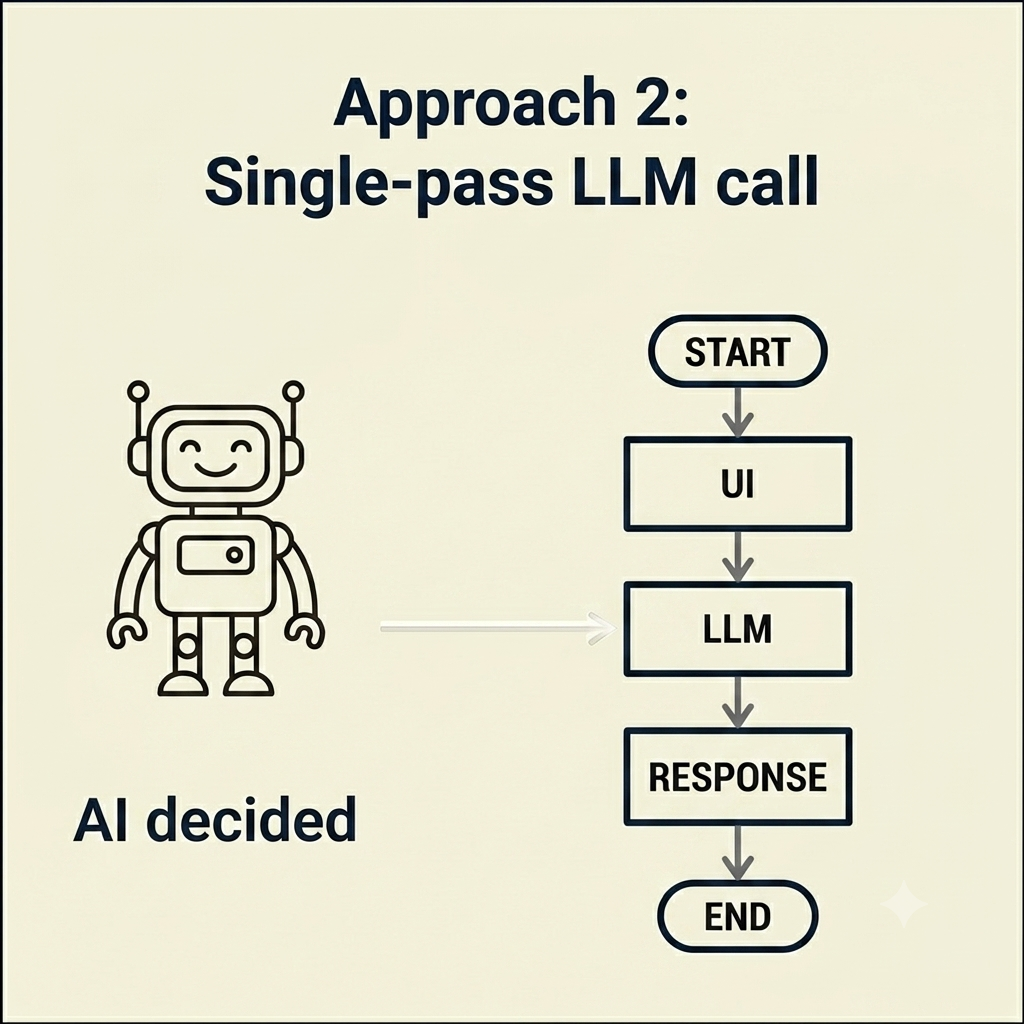
Approach 2.
Single-pass LLM call
In this approach, a message the user sends—be it a hand-typed prompt, or in a slightly more sophisticated version, a UI that builds a well-formed prompt under the hood—gets to the LLM and it generates a response and presents it. One shot. No loop. The LLM gets the prompt, returns the answer, done.
(Editor: My em dashes are explicitly and mindfully being used by me, a human, not an LLM 😊.)
Oracle’s piece on agent loops calls this single-pass and uses chatbots as the example (Oracle). A modern Claude-like chatbot is a single-pass, but it may have an agent loop running across many turns within that pass. The “chatbot equals single pass” is convenient for explanation. But reflect it should be reflected more deeply as required by your audience.
An example is a thoughtful UI that constructs a complex LLM prompt with topic, audience, and style constraints baked into it, plus a set of “boundary” rules set up by the human ahead of time. It sends the whole package to the LLM, gets back a well-formed response, and presents it to the user or to the program for formatting as necessary. The intelligence lives in the prompt design and the LLM’s output. There’s no feedback loop proper. The model can’t see whether its answer worked and then try again.
(If you’re reading carefully, you’ve already guessed at what approach my Res-o-matic.com application lives. We’ll get there!)
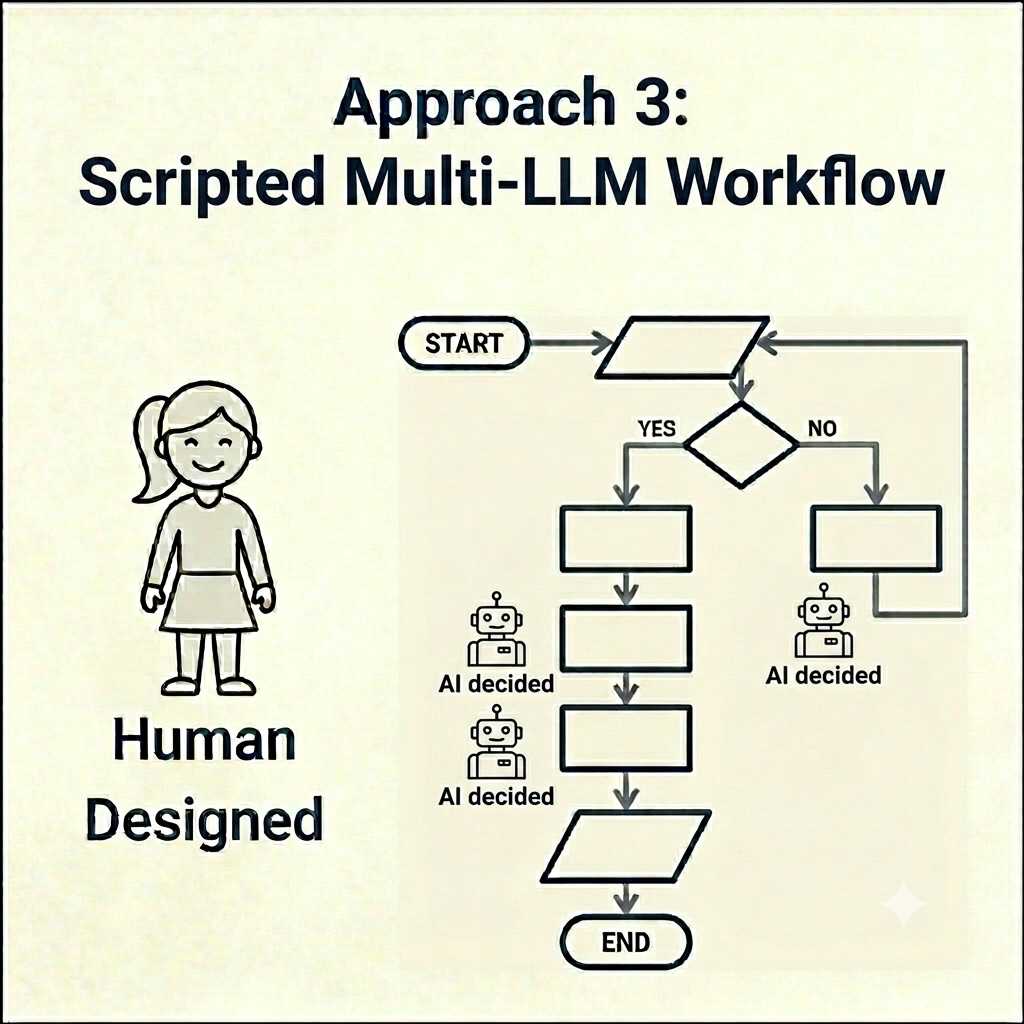
Approach 3.
Scripted multi-LLM workflow
In this approach, multiple LLM calls are written into a human-designed flow. This is the AI-era evolution of the word workflow. It’s where the vocabulary gets sticky, because the pre-LLM term “workflow” may have the traditional meaning (as in #1) to you. It may not have that meaning in current AI industry usage, as illustrated below by Palmer, so it is important to make the distinction when you are writing for multiple audiences.
Palmer’s definition, summarizing Anthropic, is a clean one-liner: “Workflow – Multiple model calls in a predefined control flow. You decide the steps, the model fills them in.” (Palmer)
The human still owns the path. The LLM does work at multiple stops along the way. Like #2, except there are more “stops” where the model gets called, results come back. The next branch is either decided ahead of time by the designer or shaped by a conditional check on the LLM’s response. The structural decisions along the orchestration are still defined by humans. The model is acting on a human-designed “map.”
An example is a competitive intelligence pipeline. LLM call (A) extracts claims from a competitor’s product page. LLM call (B) categorizes the claims (pricing, capability, audience). LLM call (C) drafts a counter-positioning paragraph for each category. Human-written code wires them together and decides what runs, in what order, with what handoffs.
The LLM doesn’t pick the path. It does key work inside the path.
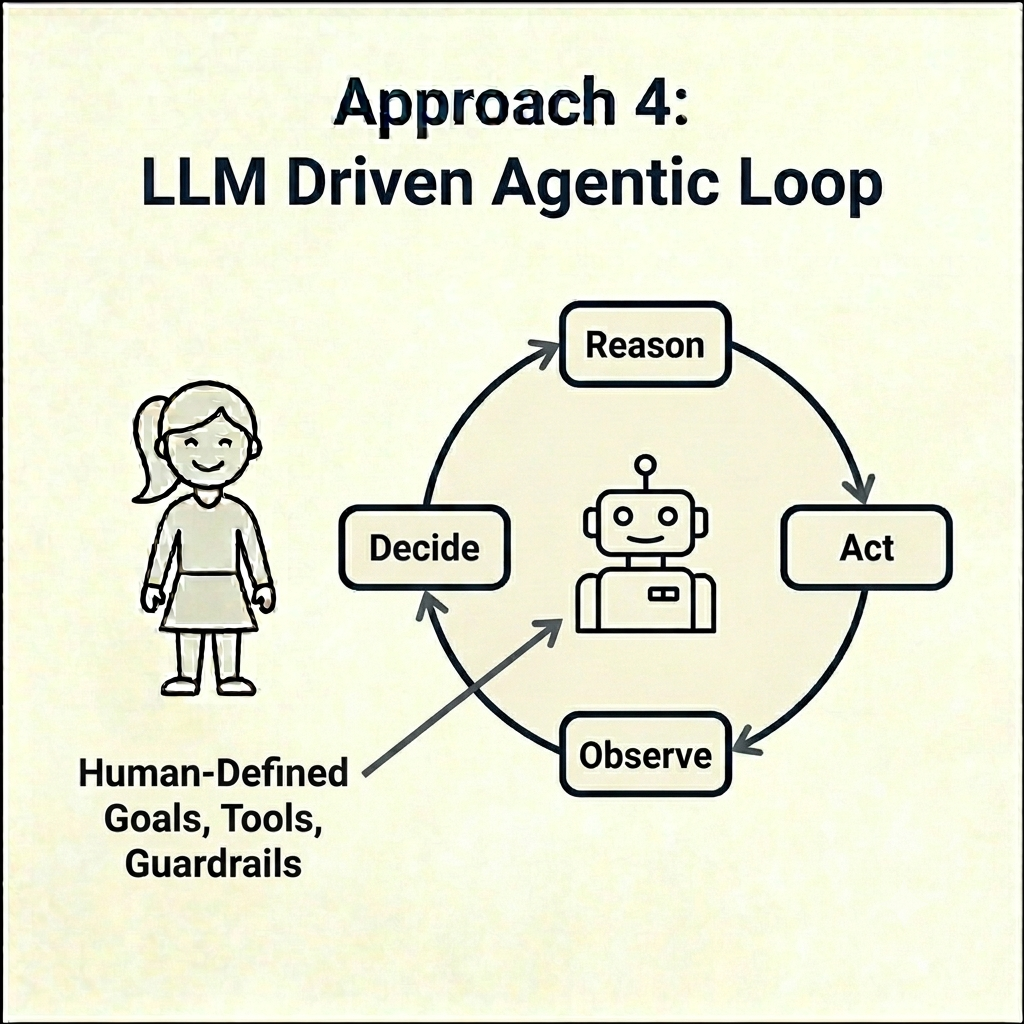
Approach 4.
LLM driven agentic loop
In this approach, an autonomous (or semi-autonomous) feedback loop is the core of the application. An agent is different from the three approaches above. Rather than executing a pre-built path, an agent is a system where an LLM picks its own next action such as deciding which tool to call, observing the result, and deciding on its own what to do next, in a loop, until it judges the task done. The designer defines the goal, the available tools, the scope of the loop (such as maximum token cost), and the guardrails (one hopes). The model chooses the route at runtime.
Anthropic’s working definition compresses to: “LLMs autonomously using tools in a loop.” And on what changes as models get better: “As the underlying models become more capable, the level of autonomy of agents can scale: smarter models allow agents to independently navigate nuanced problem spaces and recover from errors.” (Anthropic)
An example is for an evaluation of which new features in a backlog are most likely to impact revenue. An agent may have access to a data lake that has CRM data, win/loss reports, CS conversation transcripts, sales calls, and access to a library of news articles and analyst notes the PMM team has been collecting. An agentic application could decide what to do next within the constraints of user input and application design, while managing things like token cost.
The agent decided in-flight what to do, and what to do next, until it judged it was finished. It might start with win/loss data, notice that a customer-success theme keeps showing up alongside one feature, pull the CS transcripts to confirm, then check whether any analyst report names the same gap.
Rule of Thumb
- Evaluate approach 1, 2, or 3 when the path is knowable in advance. They are often cheaper, faster, and easier to debug than approach 4.
- Evaluate approach 4 when the path itself is part of the problem.
A confession:
My application Res-o-matic isn’t agentic (yet)
When I first started talking about Res-o-matic, my AI-powered tool that generates professional stories, real reference snippets, and relevant portfolio items based on my own data set and personalized to the hiring manager visitor, I called it agentic.
Honest mistake. I was using the word the way most marketing used it way back then (last fall), and frankly now (summer 2026). Which is to say, loosely.
Looking at the four-approach breakdown above, Res-o-matic.com is approach 2. A single-pass LLM call where:
- A user picks a few categories.
- The app builds a carefully constrained prompt around those categories addressing a curated set of reference materials (tagged TXT files I wrote and tagged and stored in a WordPress SQL database)
- It sends the whole package to Claude via the API
- It constructs a report based on the interpreted needs of the requester (based on the combination of elements selected), adds a few boundaries and writing style fixes, and presents it.
One pass. No agent picking its own next move.
Why did I build it that way? Honestly, I didn’t know better. Last fall, when I started, I was working with the tools I had and the patterns I’d seen. I built a data model that relies on my own tagged content rather than using MCP servers or other tools. A lead engineer of a major security firm who I know from my makerspace has told me mine is actually a clever approach (his words!) / workaround for my use case, because of its simplicity to implement and update. MCP wasn’t even on my radar then. And is overkill for this application now.
As for the business goal of a fast, controlled, defensible output report for a hiring manager to see what they want to know about me, building an agent would have been wild over-architecture.
Res-o-matic.com is evolving. The next version will probably have multiple LLM calls, partly because the WordPress architecture times out sometimes before the big “single LLM call” finishes. Breaking the work into smaller, shorter LLM calls may solve that (at least according to Claude Code). That moves it from approach 2 toward approach 3. It still won’t be agentic. Yet. The path will still be one I designed.
That’s fine. Not every problem wants an agent. Not every AI or LLM product needs to claim to be agentic. It may be inaccurate. And even if it is accurate, it may be engineering overkill and extra expense for the business problem.
“Workflows wearing costumes”
Palmer makes a approach worth reflecting on: “Assign someone to audit every internal project labeled ‘agent’ against the checklist to see how many are actually agents and how many are workflows wearing a costume.” (Palmer)
I would bet money that across the PMM teams reading this, many internal projects currently labeled “agentic” are approach 3 workflows in costume. Some are approach 2. A few are genuinely approach 4.
Why does that matter? The buyer hears “agentic” and probably assumes autonomy, adaptability, tool use — the works. They price it that way in their head. They evaluate it that way. When it turns out to be less than they thought, the product takes the reputational hit.
Labels sometimes create a lot of marketing weight that the architecture can’t lift.
Palmer’s conclusion, which I’m not going to try to improve on: “Labels matter because architecture follows them. […] Get the label wrong and you are paying for an agent when a workflow [ed. Approach 3, above] would have done the job. Get the label right and the cost, governance, and accountability questions answer themselves.” (Palmer)
Why this matters for PMMs
For product marketers, here are some things I’d be mindful of:
Pricing follows labels. If you’re positioning a workflow as an agent, you’re signaling agent-approach value (and probably agent-approach price) for workflow-approach capability. Agents typically consume ~4x more tokens than standard chat interactions, and multi-agent systems up to ~15x. (Oracle). Customers will eventually find out what they are paying for, or not.
Roadmaps follow labels. If your engineering team is building a workflow and your sales team is selling an agent, the gap shows up. Align vocabulary with what’s shipping.
Trust follows labels. “AI agent” is a category that’s still earning trust. Every workflow that gets sold as an agent makes the category itself harder to sell.
An essential corollary to this discussion:
The most impactful agentic use cases for PMMs aren’t “write my emails” or “summarize my meeting notes.”The greatest PMM impact for AI and agentic approaches is a synthesis process where evidence is scattered across systems and AI is empowered, within bounds, to investigate and act.
So, Now, I’m off to re-label my res-o-matic.com app properly! It’s still cool, it’s still AI, and it still has a cool workaround to access my own data sets. It’s just not agentic. Yet!
What are your thoughts?
Written by Gary Dietz, Product Marketing Manager
Other Stuff about AI by Gary
A 12-Hour Book, a Neuron Cleanse, and an AI Business Partner
10 Practical Ways I have Used AI (LinkedIn Post)
I’m not a programmer. I built an AI app anyway (LinkedIn Post)
Citations & references
Cited
Shelly Palmer, “How Anthropic Thinks About Agents, Workflows, and Tasks” (April 2026) — https://shellypalmer.com/2026/04/how-anthropic-thinks-about-agents-workflows-and-tasks/
Some background reading used for this essay, some of which I admit went over my head
Anthropic, “Effective Context Engineering for AI Agents” — https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
Anthropic, “Building Effective AI Agents” — https://www.anthropic.com/research/building-effective-agents
Oracle Developers Blog, “What Is the AI Agent Loop?” (March 2026) — https://blogs.oracle.com/developers/what-is-the-ai-agent-loop-the-core-architecture-behind-autonomous-ai-systems
Microsoft Learn, “Components of Agent Architecture” — https://learn.microsoft.com/en-us/agents/architecture/components-of-agent-architecture
OpenAI Agents Python SDK, “Human in the Loop” — https://openai.github.io/openai-agents-python/human_in_the_loop/